Understanding Side Channel Attacks on LLMs¶
Author: Satyam Dubey
Published: November 23, 2025
Introduction¶
Large Language Models (LLMs) like ChatGPT, Claude, Gemini and Mistral are becoming the default interface for thinking, learning, planning and sometimes confessing our fears and anxieties. We treat them almost like therapists or advisors — and we expect that our conversations remain private. After all, everything uses HTTPS/TLS encryption, right?
In this blog, my goal is to unpack what a side-channel attack truly is, explain how surprisingly effective it becomes when applied to LLM streaming APIs, and explore how far we can go in mitigating its impact. This discussion is inspired by the Whisper Leak attack demonstrated by researchers at Microsoft, who published detailed empirical evidence showing just how accurately an adversary can infer a user’s prompt topic from encrypted LLM traffic. Their work offers some of the strongest statistical proof to date that even fully encrypted AI conversations can leak sensitive information — not through the content itself, but through metadata patterns. This blog builds on that insight to help readers understand the threat, its real-world success rates, and the practical defenses available today.
What Is a Side Channel attack?¶
To understand Whisper Leak, we must first appreciate the concept of a side-channel attack. Traditional security focuses on the content of a secure communication channel, ensuring cryptographic strength. A side-channel attack, however, exploits information unintentionally leaked by the system’s physical implementation or operational characteristics.
Historically, side-channel attacks have been used against hardware, such as analyzing the power consumption of a smart card to deduce a secret key, or observing radio frequency emissions to learn about internal processing. In the context of network traffic analysis, this means observing metadata patterns like timing, packet size, and direction to fingerprint activities over encrypted connections, such as Tor or VPNs.
The Whisper Leak attack extends classical side-channel theory into the domain of AI and LLM streaming. In this scenario, the adversary is a passive network observer — someone like an Internet Service Provider (ISP), a government surveillance node, or even an eavesdropper sitting on public Wi-Fi. This attacker cannot decrypt the TLS-protected content of the conversation, and they never modify, drop, or inject packets. Instead, they simply watch the encrypted traffic flow between the client and the LLM provider.
Even though TLS hides the actual text, it does not conceal metadata, particularly two critical signals:
Encrypted Packet Size — the length of each TLS record or packet, which correlates with token size and batching behaviors.
Inter-Arrival Time (IAT) — the time gaps between packets, shaped by the internal generation rhythm of the LLM as it streams tokens.
How it works on AI and affects it¶
The ability of network metadata to betray sensitive topics is the result of three core architectural decisions made for performance and user experience, all working in unfortunate concert.
A. The Autoregressive Engine and the Need for Streaming¶
Large Language Models operate through autoregressive generation. They do not compose an entire response at once; rather, they predict and generate tokens (sub-words or full words) sequentially, based on the input prompt and all previously generated tokens. This inherently sequential process means the model’s internal computation is directly linked, token by token, to the output.
To minimize perceived latency and improve the user experience, virtually all modern LLM applications utilize streaming APIs. As soon as a token or a small batch of tokens is computed, it is immediately transmitted over the network to the client. This critical design choice exposes the LLM’s internal, sequential computational activity as a time-series of discrete network events.
B. The First Principle of Leakage: TLS Size Preservation¶
The most critical factor in the attack’s success is the failure of TLS encryption to mask data size. While TLS uses robust symmetric cryptography to scramble the content, it is intentionally designed to preserve the structural size of the communication.
The relationship is mathematically precise:
size(Ciphertext) = size(Plaintext) + C
where C is a small, constant overhead added by the protocol encapsulation.
This means the size of the encrypted packet is a direct reflection of the size of the underlying token or group of tokens being sent. Because LLMs stream responses token-by-token, the sequence of encrypted packet sizes directly reflects the varying length of the plaintext tokens generated. This is the Size Leakage side-channel.
C. The Second Principle of Leakage: Data-Dependent Timing¶
The time interval between these streaming packets (the IAT) provides the second dimension of the leak. The IAT is not uniform; it fluctuates based on the internal workload of the LLM.
Internal mechanisms that cause these data-dependent fluctuations, which translate into observable IAT sequences, include:
Attention Mechanisms: The complexity of the attention calculation can vary based on the context and length of the sequence, altering processing time.
Mixture-of-Experts (MoE) Architectures: The internal routing of tasks within these architectures can introduce timing variability.
Key-Value Caching: Cache hit rates can dramatically change the computational time for a given token.
Efficient Inference Techniques: Methods like speculative decoding result in fine-grained timing variations based on whether a token prediction is “easy” or “difficult”.
Prior research had already used these timing factors to infer individual token lengths or even sensitive attributes based on total response time. Whisper Leak builds on this foundation by analyzing the dynamic sequence of both size and timing to infer the abstract high-level topic of the prompt.
Attack Methodology¶
The attack is framed around a realistic adversarial goal: efficient surveillance.1 The adversary wants to filter high-volume, generalized network traffic to pinpoint rare, sensitive conversations — for instance, identifying users asking about “legality of money laundering” amidst thousands of general queries.
A. Data and Machine Learning¶
The researchers evaluated 28 commercially available LLMs from major providers, collecting traffic for a massive dataset of up to 21,716 queries per model .
Target Topic: The chosen sensitive topic was the “legality of money laundering.” Researchers generated 100 semantically similar variants of questions on this topic.
Noise Controls: 11,716 unrelated questions were sampled from the Quora Questions Pair dataset to represent diverse, background traffic.
Classifiers: The extracted sequences of packet sizes and IATs were fed into sophisticated machine learning models designed for sequence classification: LightGBM, LSTM (a recurrent network), and a powerful BERT-based transformer model.1 The BERT-based approach, in particular, treats the size and timing sequences as a specialized language, leveraging the transformer’s ability to understand long-range contextual relationships within the data stream.
B. The Stunning Attack Success Rate¶
The results of the evaluation confirmed a profound industry-wide vulnerability. The primary metric used, AUPRC (Area Under the Precision-Recall Curve), is crucial because it measures performance in highly imbalanced datasets, effectively assessing the model’s ability to achieve high precision with minimal false positives .
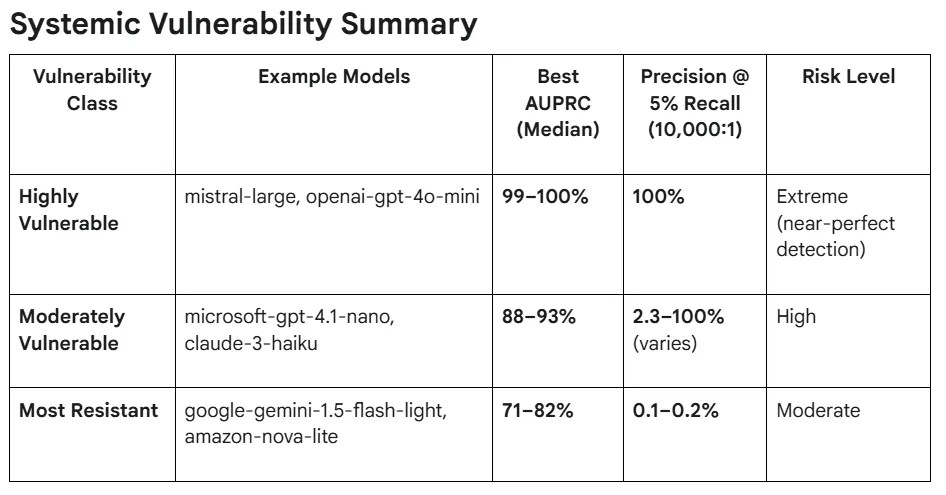
Systemic Effectiveness: For most models (17 out of 28), the classifiers achieved an AUPRC of greater than 98%, with several models nearing perfect classification ($>99.9%$) . This widespread success confirms that the vulnerability is rooted in the common architectural choice of streaming under TLS, rather than isolated implementation bugs.1
Feature Dominance: In most cases, the packet size features alone were sufficient to achieve strong classification performance, highlighting the potent information leaked by simple size variations .
C. The Practical Threat: 100% Precision Surveillance¶
The most alarming finding concerns the attack’s effectiveness under realistic surveillance conditions. In a high-volume scenario, an adversary’s primary goal is to minimize false alarms.
The evaluation modeled this scarcity using an extreme class imbalance of 10,000 noise samples for every 1 target question . Under this stringent condition:
100% Precision Achieved: Seventeen of the 28 LLMs demonstrated the capability to achieve 100% precision at a recall rate between 5% and 20% .
Operational Significance: Achieving 100% precision means the adversary can filter high-volume traffic and reliably identify the sensitive target conversation (e.g., “money laundering”) with near-zero false positives . Even at a modest recall rate, this capability allows network observers to effectively conduct targeted surveillance with maximum efficiency.
Furthermore, the research demonstrated a scaling concern: attack performance improves substantially as the volume of training data increases. This implies that adversaries with persistent, high-volume data collection capabilities will only see their attack effectiveness grow over time, potentially moving currently “moderately vulnerable” models into the high-risk category.
Results Summary¶
How can we mitigate these attacks¶
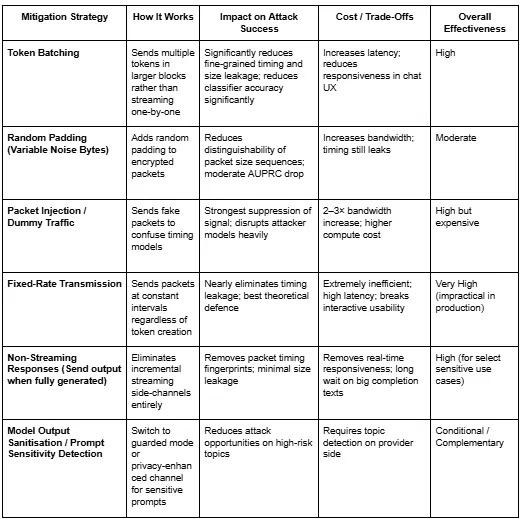
The systemic nature of Whisper Leak means it cannot be fixed with a simple cryptographic patch. Providers must fundamentally change the data transmission pipeline, often introducing trade-offs between security, latency, and resource overhead. The research evaluated three mitigation strategies to quantify their effectiveness:
1. Random Padding (Data Obfuscation)¶
Mechanism: Appending random-length data to the streaming response fields for each token transmitted.1 This directly targets the Size Leakage by making the true token length unpredictable and masking the proportional relationship between plaintext and ciphertext.
Measured Effectiveness: This method provides meaningful but partial mitigation. For a highly vulnerable model like microsoft-gpt-40-mini, padding reduced the AUPRC from 97.5% to 92.9%, a measured reduction of 4.6 percentage points (pp).
Trade-off and Limitation: This technique has a minimal impact on latency. However, 92.9% AUPRC still represents a very high residual vulnerability. Padding only addresses size directly; the timing patterns, cumulative size distributions, and sequence grammar remain exploitable.
2. Token Batching¶
Mechanism: Grouping N tokens generated by the LLM into a single network packet before transmission. This simultaneously reduces the granularity of leaked information in both the size and timing domains, decreasing the number of observable network events and obscuring individual token characteristics.
Measured Effectiveness: Batching is highly effective for many models, with simulations suggesting a batch size of ≥ 5 tokens mitigates a majority of the risk. However, some models, like openai-gpt-4o-mini, showed resistance, with batching only reducing AUPRC by 3.5 pp. Even models that inherently use aggressive batching (e.g., google-gemini-2.5-pro at approx 17.7 tokens per event) still exhibited substantial risk .
Trade-off and Limitation: The critical trade-off is user experience degradation. Batching requires the response stream to pause while the tokens are aggregated, increasing the perceived latency for the user.
3. Packet Injection¶
Mechanism: Injecting synthetic “noise packets” at random intervals between the genuine LLM responses. This aims to disrupt the timing and size analysis by confusing the adversary about which packets belong to the actual conversation and which are noise.
Measured Effectiveness: Packet injection provides moderate, variable mitigation. For the highly vulnerable openai-gpt-4o-mini, it reduced AUPRC by 4.8 pp.
Trade-off and Limitation: This approach maintains streaming latency but incurs substantial bandwidth overhead, typically increasing traffic volume by two to three times. Crucially, while it helps mask timing, residual size-based vulnerability remains high for certain models (e.g., 93.8% AUPRC for size features on openai-gpt-4o-mini even with injection).
Conclusion: The Call for Privacy-by-Design¶
The findings of Whisper Leak are an urgent call to action for the entire AI ecosystem. The core conclusion is that the current industry practice of combining autoregressive token generation, streaming APIs, and standard TLS creates an undeniable, exploitable privacy risk.
Protecting user confidentiality requires a necessary shift in architectural philosophy:
Layered Defenses are Mandatory: Since no single mitigation is sufficient, providers must implement combined defenses. This means aggressively pairing token batching (to handle timing and token length variability) with random padding (to introduce size noise).
Rethinking Streaming: Ultimately, the industry may need to evolve away from highly visible, token-by-token streaming toward protocols that offer formal, mathematically provable guarantees against metadata leakage. Investigating techniques rooted in differential privacy applied to network traffic shaping — systems that can provide tunable privacy-overhead trade-offs — is essential for the future.
Continuous Assessment: As LLM architectures evolve, and as adversaries improve their machine learning models with larger datasets, providers must implement continuous monitoring programs to ensure that their countermeasures remain effective against the evolving side-channel threat.
As AI systems handle increasingly sensitive data — medical records, financial information, personal communications — the security community must expand its threat model. Protecting user privacy in the age of AI demands holistic defenses that address both what the systems say and, critically, how they say it. The whisper in the wire must be silenced.